
The lasting relevance of VXML
Since Nu Echo’s foundation in 2002, VoiceXML has been the bread and butter of our IVR application development. We’ve been using it to create many solutions ranging from turnkey address change and identity validation modules to large scale IVR system using a custom JavaScript framework. We even open-sourced a Java VoiceXML development framework named Rivr, check it out!
While it is definitely possible to develop IVR applications in 2019 without using VoiceXML (think Dialogflow or Amazon Lex through Amazon Connect), it is still very prevalent in the large contact centers, which are an important part of our customer base. That’s why we decided to give Rasa a serious spin to find out if it could be a viable solution for developing multilingual conversational IVR applications using VoiceXML.
The use cases
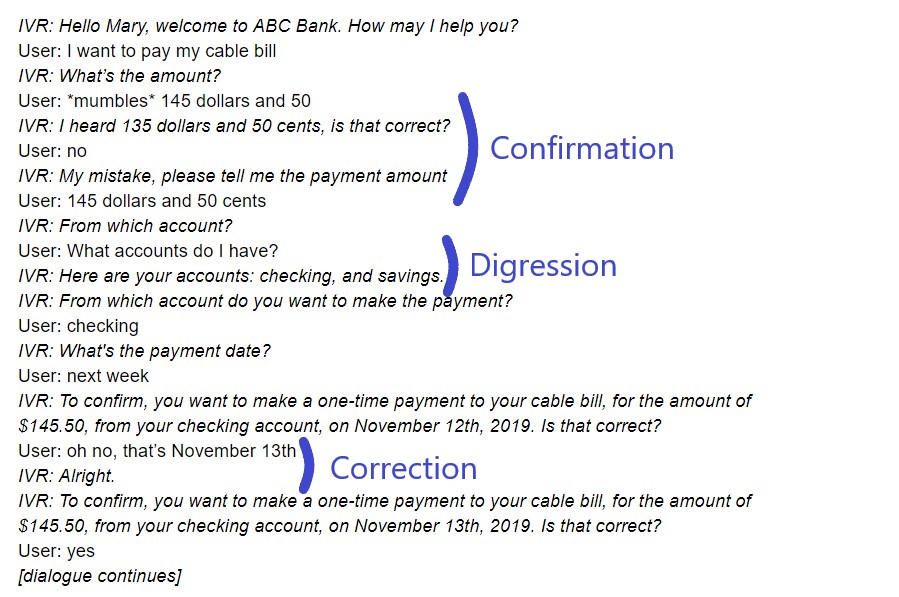
For our proof of concept, we selected some banking use cases (account balance and pay bill) that offer us interesting dialogue patterns like digressions, confirmations, corrections and global commands (cancelling a task for example).
Here is an example that mixes some of those patterns:
Introducing Rasa IVR
Developing VoiceXML IVR applications using Rasa offers interesting challenges. For one, the real-time aspect of a voice conversation that must progress if the user says nothing is quite different from the classic chatbot approach. The application can’t keep the user waiting if he says nothing, it must propose alternate and more detailed messages and eventually terminate the conversation if the user decides to stay silent.
While Rasa offers a lot of prebuilt channels, nothing exists to express the richness of VoiceXML and interpret its different outputs. As you can see from the complexity of its specification, a lot must be done to cover all the functionalities (although some of them are less used than others). Some of the most important ones that must be taken into consideration for developing basic use cases are related to constructing the output (audio files / speech synthesis), activating bargein, specifying grammars / input mode (speech and/or DTMF), and configuring confidence levels / timeouts.
The user experience (UX) must also be tailored for the voice channel since the user cannot scroll up to access the whole conversation (unless he has a supernatural memory). Some patterns like confirmation or choosing in a list are much trickier to properly implement using voice than text and widgets.
Along with those challenges come some interesting opportunities. For example, using automatic speech recognition (ASR) alongside contextual grammars allows us to greatly improve the recognition accuracy by giving a greater weight to the most probable responses. VoiceXML also offers many functionalities for a better integration to the contact center, which must be exposed (agent transfer, attached data, recordings). The synchronous aspect of the conversation also simplifies the implementation since the user can’t frantically send multiple (sometimes contradictory) inputs.
As I said earlier, this post is the first of a series that will cover different aspects of the making of our conversational banking application proof of concept. Stay tuned for more articles from my colleagues on our approach toward generating VoiceXML, dialogue management, cloud deployment and more!
Many thanks to my colleagues Linda Thibault and Guillaume Voisine for their precious advice!
