
In our field of work, we often hear “Once we’re done with the voice assistant, we’ll just use the dialog to add a chatbot on our website!” or “now that our chatbot is done, it will be a piece of cake to make a voice bot”. Seemingly, it looks like we would only need to add or remove the speech processing (speech-to-text, STT) and speech synthesis (text-to-speech, TTS) layers to magically transform a chatbot into a voicebot and vice versa (by the wave of a magic wand).
Based on our experience, we would also describe such a simple transformation as magic!
Through this blogpost, I will illustrate why with a few counterexamples.
Generating the output
Presenting complex information
Within a chatbot, text information can be enriched with images, hyperlinks, slideshows, etc. Some use cases such as navigation assistance or purchase recommendations would seem impossible to implement without those tools.
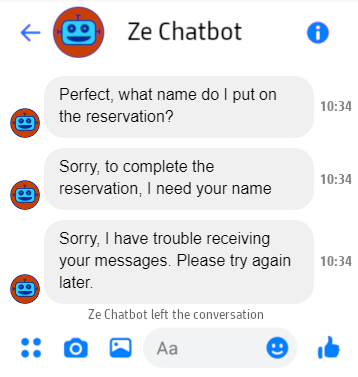
In other cases, several voice interactions would be required to reach the same result as a single visual output. For example, here is my best shot at transforming the output of a appointment scheduling chatbot for a voicebot:
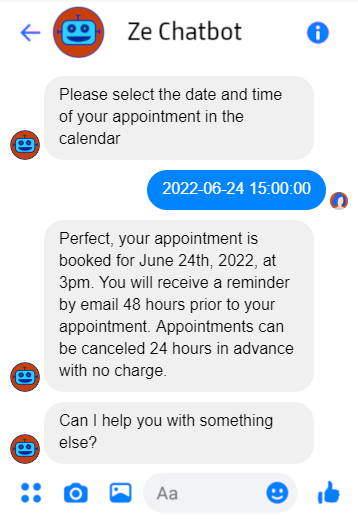
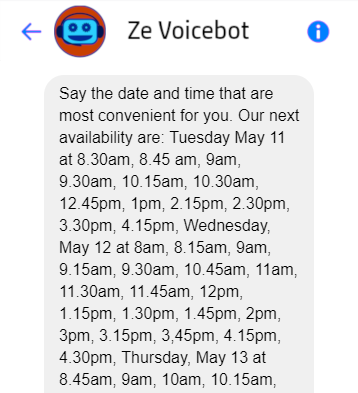
Trail of previous interactions
What does a chatbot do if the user is not paying attention, has poor memory, or has forgotten to put on their glasses? Nothing! The output remains there for the user to re-read as they see fit, which makes certain cases that are absolutely necessary in a verbal interaction become completely useless in a written conversation:
Persona and voice features
The persona (demographics, language level, personality) of the virtual agent, as well as its consistency, are important in both modes. While in text mode you have to think about the visual output of the chatbot, in voice mode, you have to look for a voice that represents the desired characteristics, while being natural, and this can limit our options. For example, trying to create an informal voice agent can be near impossible, especially when using TTS instead of a recorded voice (which also has its limitations).
Support of multiple channels
Finally, even if our use cases are channel-agnostic, our personna very simple and our agent very talkative, it is clear that we must at least be able to play different messages depending on the channel so that SSML is included in audio messages. Unfortunately, some dialog engines hardly support multiple channels and this can greatly increase the challenges of implementing a common agent for both voice and text.
Input interpretation
“What about the other way around? The user won’t send images or carousels of images to the chatbot. For sure, interpreting the input can’t be that different.” I will answer with a dramatic example. Let’s look at Bob who is trying to express what he needs to a vocal agent:
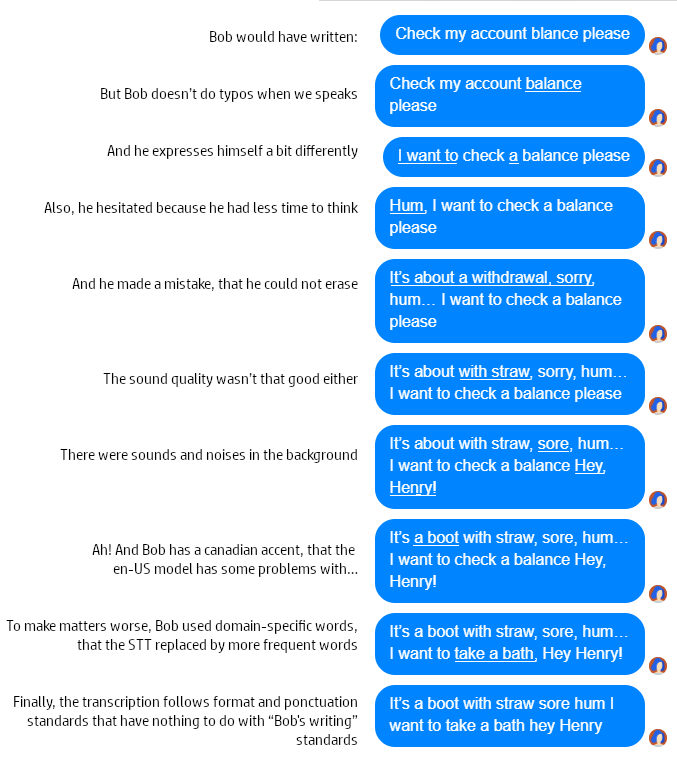
Of course, Bob and his legendary bad luck are not real, but the cases I have presented are taken from real-life examples. Even though some STT models can now ignore “mhms”, noises and secondary voices, the transcription will still have its share of errors.
Uncertainty
There are ways to reduce these errors or their impacts, whether it’s through the configuration of the engine, systematic changes of the transcription, or the adaptation of the NLP model to the sentences received. There remains, however, an additional uncertainty related to the STT which must be taken into account in the development of a voice application.
Strategies for dealing with uncertainty
To increase our confidence in the interpretation of the input, we will use more strategies for dealing with uncertainty in the dialogue of a vocal agent than in the dialogue of a textual agent.
For example, we can think of:
- Add a step to explicitly or implicity confirm an intent or an entity
- Add a step to disambiguate the input when intentions are too similar
- Enable changes or fixes
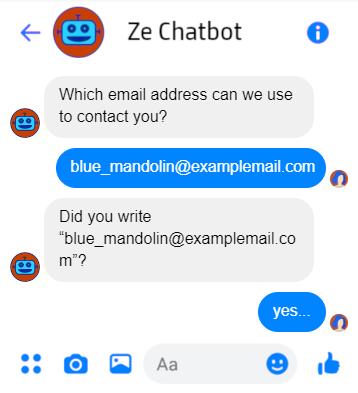
Choosing use cases
Addresses, emails or people’s names are difficult pieces of information to transcribe correctly for many reasons, but they present lesser challenges in writing. If some of these pieces of information are critical for a use case, it could be very complex, risky, or inappropriate for the user experience to implement it though a vocal agent..
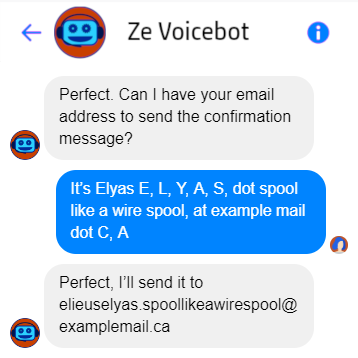
Real-time management
The last big difference between voice and text conversations is time management. A text conversation is asynchronous: the input is received in one block, and the response that follows is sent in one block. The audio, on the other hand, is transmitted continuously, so the time must be managed accordingly.
Short response time and user experience
In a vocal conversation, we are expecting a response within a few tenths of a second, while in text mode, it is completely normal to wait for much longer. Long silences on the phone are uncomfortable, and even if it is possible to play sounds or music-on-hold, between two interactions, the “…” hint cannot be replaced. It is therefore much more critical to ensure that the system is fast and to warn the user in case of a longer operation in voice mode.
Interruptions
Because voice output has a duration, the user can try to interrupt a voice agent. Supporting interruption correctly involves additional technical complexity, but also has additional impact on the dialogue. For example, we want to make the assumption that if the user says “yes” when presenting several options, this means that he chooses the first one, and we will support this case.
User Silence
Although a virtual agent isn’t discomforted by silences, the treatment of what is commonly called a no-input differs greatly depending on the mode of communication. In a voice conversation, a few seconds of silence usually means the user is hesitating or their voice is too low; an appropriate help message will therefore be played.
In text mode, it is useless to harass the user with error messages because the absence of input is treated like any inaction on a website: after a determined time, the user will be disconnected if necessary, and the conversation is ended.
So, finally…
How then does one answer the question: “What can be reused from a voice agent to create a chatbot or vice versa?” The answer is very nuanced and a little disappointing. Switching from a voice agent to a chatbot will generally allow more reuse because the former is generally more restrictive: perhaps it will be enough to adapt the messages a little, to add or remove a few dialogue paths.
However, in both cases, it is important to take a step back and re-evaluate our use cases and our persona: are they appropriate, feasible and realistic on this new channel? For what comes out of this questioning, business rules and high-level flows of the dialogue can probably be reused. The NLU model (textual data, organization of intentions and entities) and the messages of one may serve as a basis for the other, but will be subject to change. Indeed, the approach will have to be adapted to the results of user tests and data collection, so that the user experience does not suffer in favor of the simplicity of development.
