
In our previous series on developing conversational IVR applications using Rasa, we described our approach to add VoiceXML support to the platform and develop a convincing banking demo using some advanced dialogue patterns. The custom dialogue management strategy created for the project, based on a stack of actions, was completely programmatic. While this strategy allowed us to fulfill our complex requirements, we were not completely satisfied with it (we will elaborate on that in another post) and felt we were missing something by not tapping into Rasa’s machine learning potential.
We addressed this by developing a technical support text-based bot from real conversations and produced a working prototype that leveraged Rasa ML-based stories. With the experience and knowledge gained, we heavily reworked our dialogue management strategy to make it more compatible with the other Rasa components (more on that in the next installment). We also created a reusable IVR application development framework that will allow us to deliver impressive conversational experiences to our clients.
We have now completed a first version of the new framework and we reimplemented our banking demo from the ground up. The main components of this framework are:
- Dialogue management (with custom unit and integration test frameworks)
- Response generation (the main dish of this post)
- VoiceXML connector (to communicate with the VoiceXML platform)
This new series will focus on dialogue management and our new approach to response generation.
Now, let’s hop to the main topic of this post: response generation.
A NLG server, what for?
By default with Rasa, the bot responses are bundled in the domain file. While easy to manage for basic textual applications, we quickly reached the limits of this approach for our IVR application requirements. The first one is multilingualism; we want to build a single application that supports multiple languages (English and French more often than not) and Rasa offers no support in the domain file for this. We also need to produce complex, structured and highly dynamic responses for which the basic slot string replacement mechanism is not sufficient. We have to create JSON structures that contain variable lists of elements (grammars, audio concatenation) and objects with dynamic properties (thresholds, timeouts, etc..) to properly express the richness of VoiceXML.
Enters the NLG (Natural Language Generation) server, which is an extension mechanism offered by Rasa that allows us to externalize the response generation in a separate service. By implementing a simple REST interface, we can generate whatever response we want based on a requested template ID and the conversation state (tracker). This allows us to construct responses that follow our JSON VoiceXML protocol which will be consumed by the Rivr bridge. For a quick refresh on the topic, you can refer to the excellent post from my colleague Karine Déry!
What is interesting with this approach is that we can use it in stories as well as in actions, where we can have much more control with complex variables, progressive error message indices and more. In all cases, we keep track of the language in the tracker using a special unfeaturized slot.
Resources, resources, resources…
Developing a VoiceXML IVR application requires providing the proper resources to the VoiceXML platform.
Audio files
While TTS (text-to-speech) has made tremendous progress in the last few years, audio files recorded by professional voice talents still offer a more natural and expressive output. One of the challenges of using audio files is to fluidly render complex dynamic entities like dates and amounts. To do so, we usually use audio concatenation, which requires a proper segmentation of the elements to render (separate audio files for days, months and years for a date, for instance) with the proper intonation. Some code must then be written to properly translate an entity value in the correct audio sequence, which will finally be returned by the NLG server.
For example, in our banking demo, playing 507.18$ requires playing the following sequence:
- amount/500_mid.wav (five hundred);
- amount/07_dollars_rising.wav (seven dollars);
- amount/and_18_cents_final (and eighteen cents)
Here we used a final intonation for the last audio file because it is located at the end of a sentence. Had it been in the middle, a different intonation would have been chosen. Recording large batches of small audio files for concatenation requires a consistent voice talent, good coaching and tight post-processing to maximize fluidity.
Speech grammars
We currently use SRGS speech grammars in conjunction with Nuance’s ASR to interpret the user utterances, but statistical grammars (SLM/SSM) could also be used. Both allow us to produce a NLU result without Rasa (or another) NLU engine. Those grammars allow constraining what the user can say in certain contexts and can be optimized to maximize accuracy depending on what is asked from the user while still supporting digressions. Activating the proper grammars depending on the application state is a crucial aspect of maximizing NLU efficiency.
Other approaches are possible, like combining a speech-to-text (STT) engine with a separate NLU engine (e.g., Rasa NLU). This will eventually be further explored but for the time being, using speech grammars offers us a good balance between performance and simplicity.
Serving resources
In our current implementation, the NLG server is also responsible for serving those static resources to the VoiceXML platform (audio files) and the Nuance ASR (grammars). Should the need for dynamic grammars arise (to recognize elements found in the user account for example), it would be easy to enhance our server to generate them.
Crafting a complete response
The various response elements in our applications are defined in a custom structured YAML file format that links together the state of the dialogue, the associated resources and the dynamic content.
Here is a first snippet of our English resource file that describes our main menu (there is also a French equivalent with the same structure):

We can see that responses, which are composed of prompts and grammars, are organized in a hierarchical manner that reflects the application structure. Referring to a response in a Rasa story is as simple as using an utter action (utter_main_menu.initial for example). Doing so in an action is also very simple.
If we go deeper into the details, we can make a few interesting observations:
-
-
- The intents grammar (specified using the special _grammars key) is defined once at the top-level of the main menu and applies to each response (unless overridden) to avoid repetition.
- For the reentry response, we override the active grammars to add the support for allDone, which recognizes that the user has no other request (by saying no thanks for example).
- There are progressive messages for when the user doesn’t speak (no_input) or when there is a recognition error (no_match).
Here is another interesting example: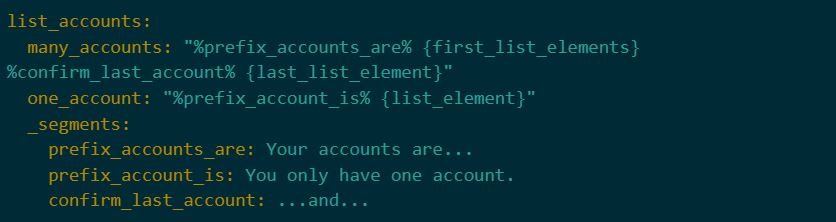 Here we are introducing our mini template language that is used for audio concatenation for outputting dynamic content. We can see that we are defining the static bits of the prompt under the special _segments key so they can easily be referred to in the template (using %segment_name%). The dynamic parts must be part of the NLG server request and may consist of further segment references or instructions for generating text-to-speech (TTS).
Here we are introducing our mini template language that is used for audio concatenation for outputting dynamic content. We can see that we are defining the static bits of the prompt under the special _segments key so they can easily be referred to in the template (using %segment_name%). The dynamic parts must be part of the NLG server request and may consist of further segment references or instructions for generating text-to-speech (TTS).
So, upon receiving an adequate request, the NLG server will find the matching response template, identify the required resources, inject the variables and assemble a complete response usable by the VoiceXML connector.
Regarding integrity
An application can rapidly become very complex with loads of resources. To ensure that every grammar is properly defined and that each audio file is recorded (and that we don’t have extra files hanging around), we have developed integrity reports that ensure that every resource defined in our definition file refers to an existing file. Those reports can also be used as an input for the team responsible for recording the audio files.
The only missing piece to our puzzle are application references which can be used to ensure that the resources in our definition files are really used by the application.
As you have seen, the NLG server is a fundamental piece in our conversational IVR application development approach with Rasa. It allows us to easily specify contextual and multilingual responses composed of prompts and grammars that can seamlessly be referred to by the stories and the custom actions. Stay tuned for the next installment where we will introduce our new dialogue management approach!
